Data Loading and Writing Utilities#
The database layer of OctaiPipe provides an interface for connecting to databases to load and write data to and from storage. This is beneficial as it enables:
Storing large volumes of data - Databases can store larger volumes of data compared to local systems, so providing an interface for retrieving and writing data is crucial for to-scale solutions.
Sharing data - In order to share data and results, a shared file system that can be reached by multiple users is needed. Being able to connect to a shared database enables this.
Interaction with the database#
For each data store type, there is a client, source (data loader), and a sink (data writer). A diagram showing how the client, source, and sink for InfluxDB interact with the database is shown below. The diagram shows how the InfluxDataLoader and InfluxDataWriter inherit from the base Source and Sink classes. They both also inherit from the InfluxClient, which connects to InfluxDB.
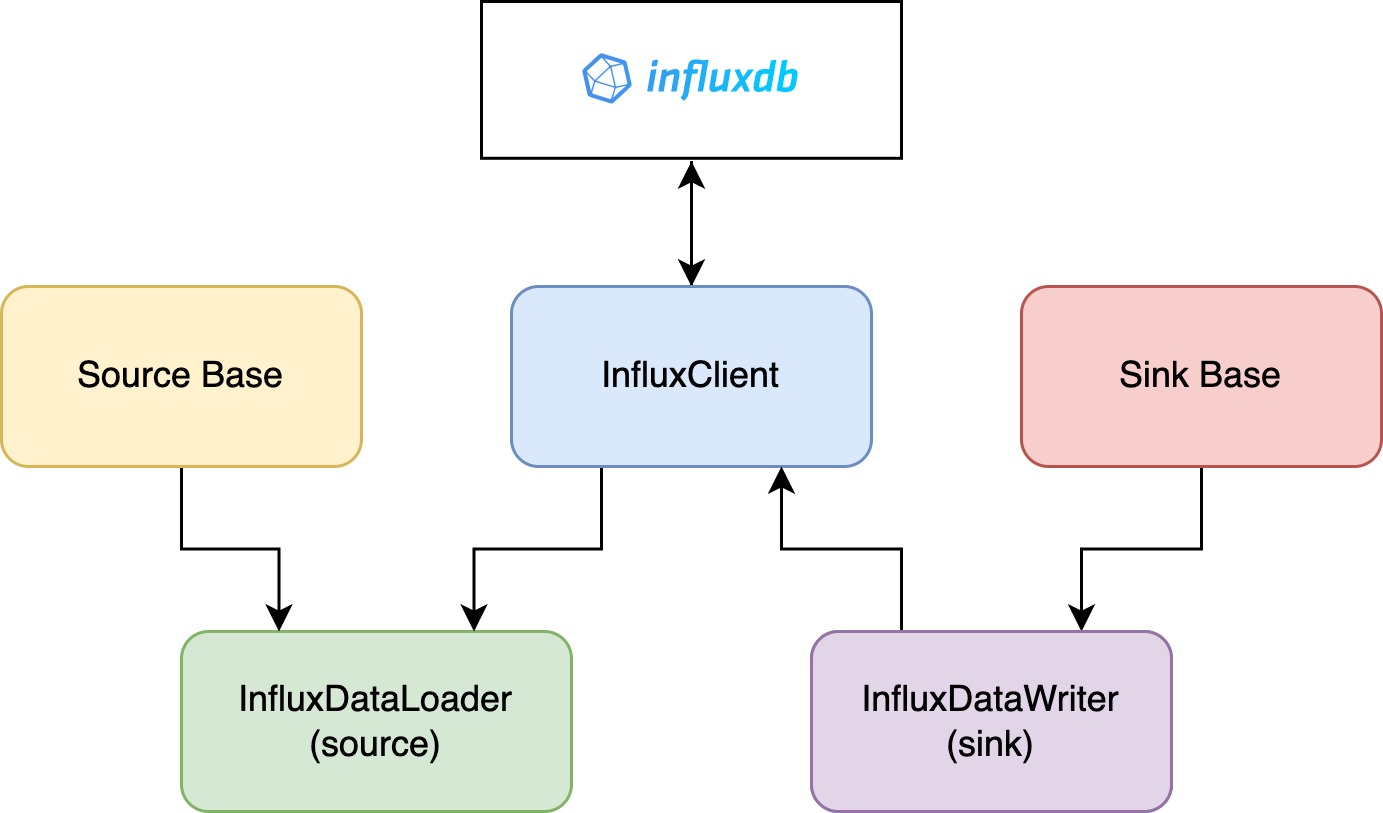
The client is set up to connect to the database and is unique for each database type. For example, the InfluxClient class sets up a connection to InfluxDB using connection credentials provided in configs or from environment variables.
Configuring data stores in OctaiPipe#
The configuration of data loading and writing in OctaiPipe has the same top-level components and structure for all data stores.
There are input_data_specs and output_data_specs for where to read and write
the data respectively. Each of these contains a dictionary of device IDs (relating to
the device ID in OctaiPipe Portal). For each device ID, there is a list of data specs.
You can also provide a default spec that is used for all devices not specified.
Each spec contains the field datastore_type which specifies where to read data from.
The available types are:
influxdb
mqtt
sql
local
csv
The settings field contains the specific configurations for the datastore type.
The configurations for each type are in the sections below.
The connection_params are optional and tell OctaiPipe how to connect to the datastore.
In the example below, we specify input_data_specs for device device_0 to read from
influx and a local CSV. The default specs tell any other devices to read only from influx.
The output_data_specs tell device_0 to write to mqtt while all other devices will
pick up the specs from default and write to influx.
1# input config
2input_data_specs:
3 device_0:
4 - datastore_type: influxdb
5 settings:
6 query_template: |
7 from(bucket: [bucket])
8 |> range(start: [start], stop: [stop])
9 |> filter(fn:(r) => r._measurement == [measurement])
10 |> filter(fn:(r) => [fields])
11 |> drop(columns: ["_start", "_stop", "_batch",
12 "table", "result", "_measurement"])
13 query_config:
14 start: "2022-01-01T00:00:00.000Z"
15 stop: "2022-01-02T00:00:00.000Z"
16 bucket: bucket_1
17 measurement: metric_1
18 connection_params:
19 url: "http://influxdb:8086"
20 org: "my-org"
21 token: "my-token"
22 - datastore_type: local
23 settings:
24 query_config:
25 filepath_or_buffer: ./path/to/csv_file.csv
26 default:
27 - datastore_type: influxdb
28 settings:
29 query_template: |
30 from(bucket: [bucket])
31 |> range(start: [start], stop: [stop])
32 |> filter(fn:(r) => r._measurement == [measurement])
33 |> filter(fn:(r) => [fields])
34 |> drop(columns: ["_start", "_stop", "_batch",
35 "table", "result", "_measurement"])
36 query_config:
37 start: "2022-01-01T00:00:00.000Z"
38 stop: "2022-01-02T00:00:00.000Z"
39 bucket: bucket_1
40 measurement: metric_1
41 connection_params:
42 url: "http://influxdb:8086"
43 org: "my-org"
44 token: "my-token"
45
46# output config
47output_data_specs:
48 device_0:
49 - datastore_type: mqtt
50 settings:
51 topic: some_topic
52 connection_params:
53 broker_address: mosquitto
54 port: 1883
55 username: mqtt-user-1
56 password: alligator1
57 client_id: device-1-publisher
58 use_tls: false
59 default:
60 - datastore_type: influxdb
61 settings:
62 bucket: output-bucket
63 measurement: my-measurement
64 connection_params:
65 url: "http://influxdb:8086"
66 org: "my-org"
67 token: "my-token"
InfluxDB Configuration#
The connection parameters for influx take the url, org and token for the client to
connect. If influx is running on the same device and docker network as OctaiPipe,
the influx url can just be the name of the container and port, e.g. http://influxdb:8086.
In settings, a query_template can be provided as string or query_template_path
can be provided as a path to a query_template. query_config can then be used to
provide key-value pairs to replace the place holders [key] in the template.
If you wish to just provide a full query, with no placeholder, just set the full query
in query_template and provide no query_configs.
1# Influx template
2from(bucket: [bucket])
3 |> range(start: [start], stop: [stop])
4 |> filter(fn:(r) => r._measurement == [measurement])
5 |> filter(fn:(r) => [fields])
6 |> drop(columns: ["_start", "_stop", "_batch",
7 "table", "result", "_measurement"])
1# Influx load config
2input_data_specs:
3 default:
4 - datastore_type: influxdb
5 connection_params:
6 url: "http://influxdb:8086"
7 org: "my-org"
8 token: "my-token"
9 settings:
10 query_template_path: ./configs/data/influx_query.txt
11 query_config:
12 start: "2022-01-01T00:00:00.000Z"
13 stop: "2022-01-02T00:00:00.000Z"
14 bucket: bucket_1
15 measurement: metric_1
16 tags:
17 TAG1: some_tag
1# Influx write config
2output_data_specs:
3 default:
4 - datastore_type: influxdb
5 settings:
6 bucket: test-bucket
7 measurement: live-model-predictions
SQL Configuration#
SQL, like influx, takes a query template and fields to replace. If you wish to just
specify a SQL query, just put the whole query as query_template and submit no query_config.
The connection params consists of the ODBC connection string for the database.
1% SQL template
2SELECT [cols] FROM [table] WHERE [conditions];
1# SQL loading config
2input_data_specs:
3 default:
4 - datastore_type: sql
5 connection_params:
6 connection_str: some_connection_str
7 settings:
8 query_template: |
9 SELECT [cols] FROM [table] WHERE [conditions];
10 query_config:
11 table: my_table
12 cols:
13 - col1
14 - col2
15 conditions:
16 - "col1=1"
17 - "col2<4"
1# SQL writing config
2output_data_specs:
3 default:
4 - datastore_type: sql
5 settings:
6 data_type: dataframe
7 db_table: output-table
MQTT Configuration#
MQTT is a lightweight messaging protocol used to send messages through a message broker. A publisher adds messages with a specific topic to a queue on the broker and clients that subscribe to the same topic can read them. It is fast and lightweight, often used for real-time, IoT applications.
OctaiPipe implements MQTT using Eclipse’s Mosquitto MQTT broker.
This can be installed on devices using the install_mosquitto_on_devices function from
octaipipe.data. The function takes either device_ids or device_groups, a list
of device IDs or device groups to start the broker on.
To use MQTT for data loading and writing, you can use OctaiPipe’s built in MQTT data loading and writing functionalities.
MQTT Data Loading#
An example data loading configuration is shown below. The connection_params dictionary
contains information given to the client on initialization, mainly used to connect to
the broker. Topic is the only required argument, secifying which topic to subscribe to.
The broker_address is the hostname of the device running the broker. If using MQTT
with OctaiPipe edge deployments or Federated Learning, this should be set to mosquitto.
The port is the port to connect on. This is 1883 by default when setting Mosquitto
up with OctaiPipe. Username and password are credentials used for the broker if set
up. Client ID is the name the client connects with. A default is assigned if not given.
The user can also speciy use_tls to True in order to connect using TLS encryption.
For MQTT, datastore_type should be mqtt in lowercase. The query_template_path
is not used, and can be left empty. The return type is specified by the query_type
field and can be either dataframe to return a Pandas DataFrame or json to return
a list of dictionaries.
The query_config dictionary configures data loading at runtime. Time to wait for
messages when loading data is set with loop_seconds (defaults to 0). If a key in
the message retrieved is the index of the data, this can be specified with index_key.
Finally, if the topic needs to be set/changed when calling the load functionality, this
can be set with topic. This can be used for example in FL, to specify one topic for
the input_data_specs and one for evaluation_data_specs. The add_tags
argument is a list specifying anytags to add to the data when reading. For a dataframe
this will be added as a new column and for JSON will be added to each record dictionary.
If messages are nested in a dictionary where the data needs to be accessed from a
specific key, the message_name argument can be used to retrieve the data.
1input_data_specs:
2 device_0:
3 - datastore_type: mqtt
4 connection_params:
5 broker_address: mosquitto
6 port: 1883
7 username: mqtt-user-1
8 password: alligator1
9 client_id: sensor-3-subscriber
10 use_tls: false
11 settings:
12 query_type: dataframe # dataframe/json
13 query_config:
14 loop_seconds: 1
15 index_key: time
16 topic: sensor-3
17 add_tags: []
18 message_name: some-name
MQTT Data Writing#
Below is an example of an MQTT data writing config output_data_specs.
The connection_params are the same as for data loading, except the topic
specifies where to publish messages to rather than what to subscribe to. Topic has to
be specified either here or in the mqtt parameters below.
The datastore_type should be mqtt. The mqtt dictionary specifies the
writing configurations at runtime. The topic is what topic messages should be
published to, and will overwrite a topic specified in connection_params. To write
a full dataset as one message, set write_as_one to True. Otherwise, each record (row)
will be written as a single message. The write_index field specifies whether to
add the index of a Pandas DataFrame as a field when writing. To save the last message
sent to the queue, retain can be set to True. This can be useful when we want to add
messages to be consumed by a subscriber that is yet to connect. A dictionary of tags
can be added to send the message as a dictionary with the data in the field with name
message_name (defaults to “data”) and additonal key-value pairs for each tag.
1output_data_specs:
2 device_0:
3 - datastore_type: mqtt
4 connection_params:
5 broker_address: mosquitto
6 port: 1883
7 username: mqtt-user-1
8 password: alligator1
9 client_id: sensor-3-publisher
10 use_tls: false
11 settings:
12 topic: sensor-3
13 write_as_one: false
14 write_index: true
15 retain: false
16 tags:
17 tagId: data_tag_0
18 message_name: data_field
Local data Configuration#
Local data loading has no connection parameters. However, it is important to
note that if you are running OctaiPipe with the default octaipipe user, you might
need to give the octaipipe user on your machine read and write permissions to the files/folders
you wish to read/write from.
1# Local loading config
2input_data_specs:
3 default:
4 - datastore_type: local
5 settings:
6 query_type: csv # can be csv or excel
7 query_config:
8 filepath_or_buffer: path/to/file.csv
9 skiprows: 2
The query type can be set to ‘csv’ or ‘excel’, which uses Pandas read_csv or read_excel.
Query config is a dictionary, where each key-value pair represents an argument to
the underlying Pandas function. In the example above, filepath_or_buffer specifies
the path to the data and skiprows specifies how many rows to skip at the beginning
of the file.
For excel, the minimum arguments would be io for the filepath and sheet_name if
the default first sheet should not be used.
More arguments can be found for Pandas read_csv and read_excel below:
Read CSV: read_csv.
Read excel: read_excel.
For data writing, the configs simply specify the file_path, where the extension
determines how data is written. Ending the path with ‘.csv’ will make use of Pandas
write_csv. Options and functions are below:
.csv uses Pandas
to_csv.xlsx uses Pandas
to_excel- note, .xls not supported since pandas 2.0.json uses json package
json.dump.zip uses
shutil.make_archive
The to_csv and to_excel functions can also be given arguments by including
a dictionary called write_config of argument names and values. An example is below:
1# Local writing config
2output_data_specs:
3 default:
4 - datastore_type: local
5 settings:
6 file_path: path/to/file.csv
7 write_config:
8 index: true
9 sep: ';'
NOTE: When you use data from a local filestorage on your device, you will need to make sure that OctaiPipe has read and write access to the files you want to access. To ensure this, you need to run the following code on your device before you run a deployment:
sudo chown -R root:49999 {replace with folder path}
If you cannot change file permissions on your machine, you can run OctaiPipe with root images, see OctaiPipe Images.
CSV Configuration#
Specific configurations for CSV data loading and writing. This data store type is less flexible than local data loading and writing, but is useful for simple CSV files.
CSV Data Loading Configuration#
CSV data loading supports specifying delimiters, handling headers, setting index columns, and excluding specific columns. The configuration is based on the CsvDataLoader class.
Example of input data specifications for CSV:
1input_data_specs:
2 device_0:
3 - datastore_type: csv
4 settings:
5 file_path: /data/sensor_measurements.csv
6 delimiter: ';' # Semicolon-separated file
7 headers: true # File has a header row
8 index: # Columns to use as index
9 - timestamp
10 - sensor_id
11 exclude: # Columns to exclude from processing
12 - raw_data_hex
13 - metadata_column
CSV Data Writing Configuration#
CSV data writing allows specifying file paths, writing mode, and delimiter. The configuration is based on the CsvDataWriter class.
Example of output data specifications for CSV:
1output_data_specs:
2 device_0:
3 - datastore_type: csv
4 settings:
5 file_path: /outputs/processed_sensor_data.csv
6 delimiter: ',' # CSV delimiter (comma by default)
7 append: false # Overwrite existing file
8
9 device_1:
10 - datastore_type: csv
11 settings:
12 file_path: /outputs/incremental_log.csv
13 delimiter: ';' # Semicolon-separated file
14 append: true # Append to existing file if it exists
Key Configuration Options#
Input Configuration:
file_path: Path to the CSV file
delimiter: File separator (,, ;, t, etc.) Defaults to comma
headers: Whether the file has a header row. Defaults to true
index: Columns to use as DataFrame index. Defaults to []
exclude: Columns to exclude from processing. Defaults to []
Output Configuration:
file_path: Destination path for the CSV file
delimiter: Column separator (defaults to comma)
append:
true: Append to existing file
false: Overwrite existing file (default behavior)
NOTE: As with the local data store type - When you use data from a local filestorage on your device, you will need to make sure that OctaiPipe has read and write access to the files you want to access. To ensure this, you need to run the following code on your device before you run a deployment:
sudo chown -R root:49999 {replace with folder path}
If you cannot change file permissions on your machine, you can run OctaiPipe with root images, see OctaiPipe Images.