Preprocessing Step#
To run locally: preprocessing
Real-world data is messy: it is often created, processed and stored by different humans, and automated processes. As a result, it is typical that a dataset contains missing individual fields, manual input errors, duplicate data, and other errors. Data preprocessing is an essential step in a data science pipeline, which transforms the data into a format more easily and effectively used by a statistical/machine learning model.
steps#
OctaiPipe’s Preprocessing step provides the following options to preprocess raw data:
Step |
Description |
|---|---|
|
Uses linear interpolation to impute missing numeric values in the data. Numeric value dtypes are converted to float by default. |
|
Removes columns with variance below |
|
Creates Remaining Useful Life (RUL) target based on linear or piece-wise linear degradation models (details below). |
|
Encodes a specified set of categorical columns. |
|
Scaling columns into the same scale. |
Currently, OctaiPipe natively supports the following encoders and scalers from
scikit-learn:
One-hot encoder
Ordinal encoder
MinMax scaler
Standard scaler
Robust scaler
Config#
The following are examples of config files respectively for running the step once and periodically, together with descriptions of its parts.
Config example for running the step once#
1name: preprocessing
2
3input_data_specs:
4 default:
5 - datastore_type: influxdb
6 settings:
7 query_type: dataframe # influx/dataframe/stream/stream_dataframe/csv
8 query_template_path: ./configs/data/influx_query.txt
9 query_config:
10 start: "2020-05-20T13:30:00.000Z"
11 stop: "2020-05-20T13:35:00.000Z"
12 bucket: sensors-raw
13 measurement: cat
14 tags: {}
15
16output_data_specs:
17 default:
18 - datastore_type: influxdb
19 settings:
20 bucket: test-bucket-1
21 measurement: testv1
22
23run_specs:
24 save_results: True
25 # run_interval: 2s
26 target_label: RUL
27 label_type: "int"
28 onnx_pred: False
29 train_val_test_split:
30 to_split: false
31 split_ratio:
32 training: 0.6
33 validation: 0.2
34 testing: 0.2
35
36preprocessing_specs:
37 steps: # full list of steps will be in technical documentation
38 - interpolate_missing_data
39 - remove_constant_columns
40 - make_target
41 - encode_categorical_columns
42 - normalise
43 degradation_model: linear # linear, pw_linear
44 initial_RUL: 10
45 var_threshold: 0
46 preprocessors_specs:
47 - type: onehot_encoder
48 load_existing: False
49 name: onehot_encoder_test0
50 # version: "2.3"
51 categorical_columns:
52 - "cat_col1"
53 - "cat_col2"
54 - type: minmax_scaler
55 load_existing: False
56 name: scaler_test0
57 # version: "1.1"
Config example for running the step periodically#
1name: preprocessing
2
3input_data_specs:
4 default:
5 - datastore_type: influxdb
6 settings:
7 query_type: dataframe
8 query_template_path: ./configs/data/influx_query_periodic.txt
9 query_config:
10 start: 2m
11 bucket: live-metrics
12 measurement: live-raw
13 tags: {}
14
15output_data_specs:
16 default:
17 - datastore_type: influxdb
18 settings:
19 bucket: live-metrics
20 measurement: live-processed
21
22run_specs:
23 save_results: True
24 run_interval: 10s
25 label_type: "int"
26 onnx_pred: false
27
28preprocessing_specs:
29 steps: # full list of steps will be in technical documentation
30 - interpolate_missing_data
31 - remove_constant_columns
32 # - make_target
33 - encode_categorical_columns
34 - normalise
35 degradation_model: linear # linear, pw_linear
36 initial_RUL: 10
37 var_threshold: 0
38 preprocessors_specs:
39 - type: onehot_encoder
40 load_existing: True
41 name: onehot_encoder_test0
42 version: "2.3"
43 categorical_columns:
44 - "cat-col1"
45 - "cat-col2"
46 - type: minmax_scaler
47 load_existing: True
48 name: scaler_test0
49 version: "1.1"
Input and Output Data Specs#
input_data_specs and output_data_specs follow a standard format for all the pipeline
steps; see Octaipipe Steps.
Run Specs#
20run_specs:
21 save_results: True
22 run_interval: 10s
run_specs provide high level control of the preprocessing step run. Desciptions and options
for the config items are given in the table below.
level 1 |
level 2 |
level 3 |
type/options |
description |
|---|---|---|---|---|
|
|
if False, the step is flushed without saving any of the outputs, only use for testing. |
||
|
|
if this key is present, the step will be run periodcally at the specified interval. Value is given in minute (e.g. 2m), or in second (e.g. 10s). |
||
|
|
|
if True, the whole preprocessed dataset will be split into three sections according to the ratios below and saved with corresponding tags |
|
|
|
|
ratios defining the data split into training, validation and test, you can then use the tags for model training step subset. Note! The three floats must add up to 1.0 |
|
|
|
|||
|
|
Preprocessing Specs#
20preprocessing_specs:
21 steps:
22 - interpolate_missing_data
23 - encode_categorical_columns
24 - normalise
25 - remove_constant_columns
26 - make_target
27 degradation_model: linear
28 initial_RUL: 100
29 var_threshold: 0
30 preprocessors_specs:
31 - type: onehot_encoder # Required with `encode_categorical_columns` step
32 load_existing: False
33 name: onehot_encoder_test0
34 # version: "2.3"
35 categorical_columns:
36 - "cat_col1"
37 - "cat_col2"
38 - type: minmax_scaler # Required with `normalise` step
39 load_existing: False
40 name: scaler_test0
41 # version: "1.1"
preprocessing_specs provides control of the preprocessing steps to be performed.
steps#
The user specifies the steps to be used, out of those listed above.
Note
The execution order of the steps depends on the order of the steps list
degradation_model for make_target#
Note
This section is only applicable for run-to-failure datasets
A database containing multiple run-to-failure datasets can be used to build supervised learning models to predict remaining useful life (RUL). Supervised learning approaches require a target output set, containing the RUL at each timestep in the data. This is, however, not possible to know without a physical model of the system, and hence these datasets do not come with a target RUL output set so one needs to be built. A few common approaches are outlined below.
linear - Linear Degradation Model#
This approach follows the definition of RUL in the strictest sense, using the time remaining before failure (i.e. the remaining number of observations before the end of the dataset).
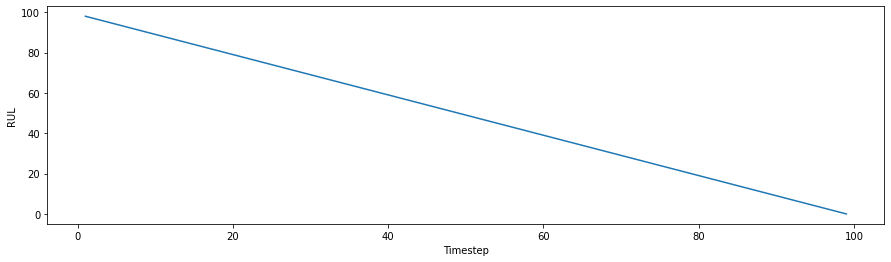
pw_linear - Piece-Wise Linear Degradation Model#
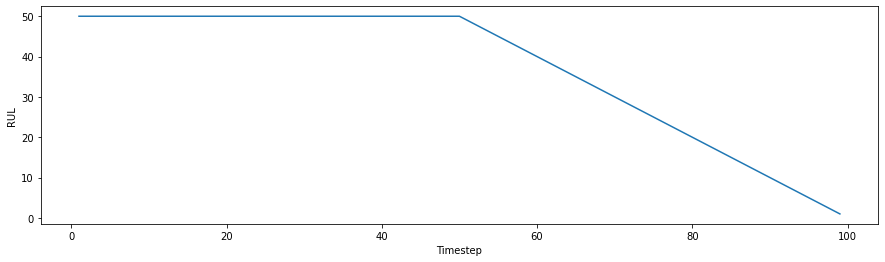
The above approach assumes that the system degrades linearly from the beginning. A more reasonable assumption would be that the system only starts to degrade after a period of time. This approach was first proposed in Recurrent neural networks for remaining useful life estimation for use on the C-MAPSS dataset, with the use of a piece-wise linear degradation model. This model sets an initial, maximum RUL value that the system exists at before linear degradation begins. This approach should provide a more realistic degradation profile and helps to prevent overestimating of RUL. It has been shown empirically to improve performance compared to the above approach for the CMAPSS dataset (Remaining useful life estimation in prognostics using deep convolution neural networks).
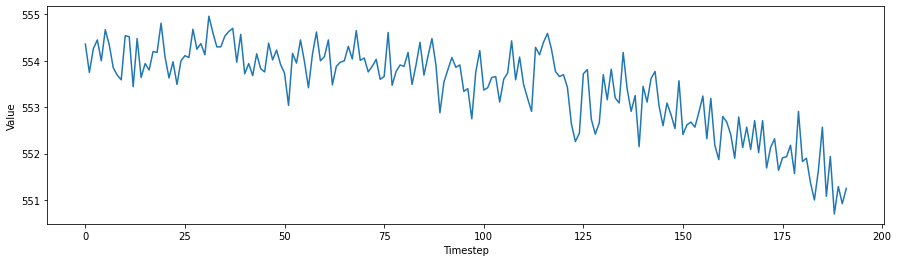
The above is sensor 7 from the dataset of the first engine unit in CMAPSS. As can be seen visually, the piece-wise linear degradation model is suitable.
initial_RUL for pw_linear Degradation Model#
Note
This section is only applicable for run-to-failure datasets
This is an integer value that defines the healthy useful lifetime of a system.
That is, in the piece-wise linear plot above, the initial_RUL is the horizontal
line set at a value of 50 time units.
preprocessor_specs#
29preprocessors_specs:
30 - type: onehot_encoder
31 load_existing: False
32 name: onehot_encoder_test0
33 # version: "2.3"
34 categorical_columns:
35 - "cat_col1"
36 - "cat_col2"
37 - type: minmax_scaler
38 load_existing: False
39 name: scaler_test0
40 # version: "1.1"
The user specifies a list of preprocessor objects— encoders and scalers— to be used.
The type is one of the following:
onehot_encoderordinal_encoderminmax_scalerstandard_scalerrobust_scaler
Note
All fitted encoders and scalers are saved and version-controlled so that the same encoders or scalers can be loaded to transform data during evaluation or inference.
If the step encode_categorical_columns (normalise) is used, at least one
encoder (scaler) must be specified, or an error will be thrown.
If load_existing is true, the user must specify the preprocessor
version to be used; if false, a new preprocessor will be
fitted, used to transform the data and will be saved.
When the preprocessing step is run periodically (typically in an inference pipeline),
all the specified proceprocessors must have load_existing: true— we must use
fitted preprocessors to transform data— or an error will be thrown.
Note that to scale the target label, the user needs to specify the name of the
target label under run_specs as explained in the following section. The same
encoder or scaler that is applied to the features will be used to fit and transform
the target label.
Run Specs#
42run_specs:
43 save_results: True
44 run_interval: 10s
45 target_label: RUL
46 onnx_pred: False
run_specs provide high level control of the preprocessing step run. Desciptions and options
for the config items are given in the table below.
type/options |
description |
|
|---|---|---|
|
|
if False, the step is flushed without saving any of the outputs, only use for testing. |
|
|
if this key is present, the step will be run periodcally at the specified interval. Value is given in minute (e.g. 2m), or in second (e.g. 10s). |
|
|
the target label in the dataset, if any.
if |
|
|
whether to use the onnx file of a fitted preprocessor to transform data. If false, the joblib preprocessor file is used. |