k-FED Clustering#
Introduction#
A major obstacle for machine learning in the industrial sector is the lack of labelled data for training supervised models. Data labelling may be impossible due to lack of data access, labour intensity and costs.
Therefore, a trustworthy, automated, unsupervised data labelling framework is crucial to unlock the potential for industrial IoT. Such frameworks often come in form of clustering, which can be used directly for anomaly detection, or to generate labels for training supervised models.
To this end, we have identified a state-of-the-art unsupervised federated clustering algorithm, the k-FED algorithm.
The k-FED algorithm#
The k-FED algorithm is a one-shot algorithm that builds on the k-means algorithm. K-means separates data points into clusters, where each data point belongs to the cluster where the distance to the cluster centroid (mean value in feature space) is the smallest. Below is an image showing the iterative process of setting centroids, assigning data points and updating centroids and cluster assignments until the model converges.
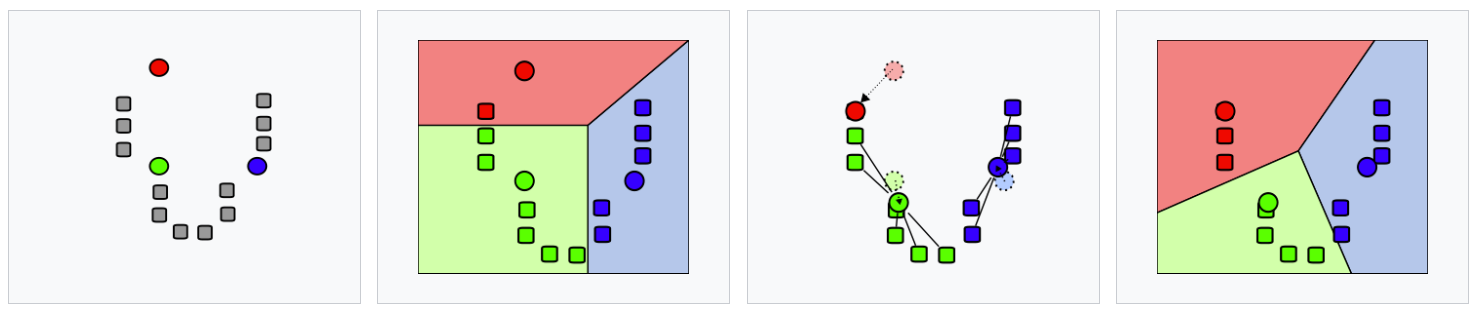
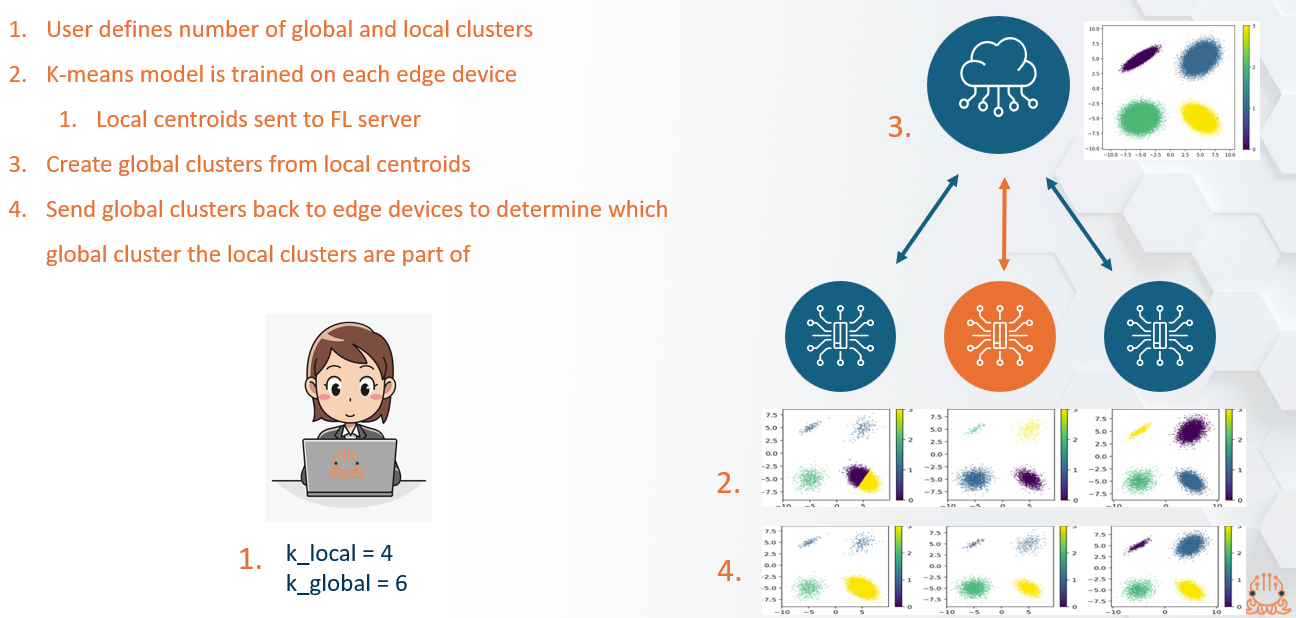
The k-FED algorithm trains a k-means model at each device, using the k-means++ initialization. The cluster centroids of each local model are then transferred to the FL server, where a global k-means model is trained from the local centroids.
The resulting model has cluster separations based on the information from all participating devices.
In order to get local cluster assignments that are consistent across devices, the global model is sent back down to each device and the local cluster assignments are updated based on the global model. Each data points will be assigned to the global cluster where its local centroid is closest to the global centroid.
Setting the k parameter#
The key parameter to set in k-means clustering is the number of clusters, k. This assumes that we have some a priori knowledge of the data, being able to estimate how many clusters we expect to see.
The same parameter is present in k-FED, but it is somewhat more involved. In k-FED,
the user sets two paramters k_local and k_global. These parameters specify the
number of clusters that each local device sets as well as the number of clusters that
the global model will have.
To anchor this to the real world, imagine we measure normal and failure states of machines in 5 separate locations. There might be a total of 10 failure states across the 5 locations. However, each individual location might only display 4 of these, with different states being present at different locations.
The k-FED algorithm allows local models to identify states at each location, and the global model then creates clusters representing the full distribution of states across locations.
It is worth noting that k_global has to be equal to or greater than k_local.
To further evaluate the k-FED model as well as the clusters it creates, you can use the OctaiPipe documentation on Evaluating k-FED.
To use k-FED for edge labeling, see Edge Labelling.
Running k-FED in OctaiPipe#
Training a k-FED model#
Training a k-FED model is done through OctaiPipe’s FL framework, OctaiFL. The same code and configuration file as for a supervised FL run can be used. There are two main differences to supervised FL.
Set the model specs for k-FED. This means setting the model type to
kFEDand model parameters for the local and global models
model_specs:
name: my_kfed_model
type: kFED
model_params:
local_params:
n_clusters: 4
global_params:
n_clusters: 8
The model is often evaluated on the same data it is trained on
This means that the evaluation data specs is often the same as input data specs. However, you can evaluate on a separate dataset if you want.
It also means that the target_label in the run_specs should be empty.
Below is sample run_specs for k-FED. Note that the backend is kmeans.
run_specs:
backend: kmeans
cycle_id:
target_label:
Inference with k-FED#
There are two ways to run inference with the k-FED algorithm. Either continuously, making predictions at an interval, or just once, getting cluster identities for a specific dataset and then stopping.
Running once#
To run inference once and get the global cluster identities for a local dataset, set the model type in your inference config to kFED, and provide the name and version number.
You will also want to set the run_specs to disable batch prediction so that all
data is loaded at once and set the max_iterations to 1, so that you stop running
inference after having run the predictions once.
Example model_specs and run_specs are below:
model_specs:
name: my_kfed_model
type: kFED
version: '5'
run_specs:
disable_batch_prediction: true
max_iterations: 1
only_last_batch: false
onnx_pred: false
prediction_period: 30s
Running continuously#
If you want to run inference continuously and get cluster predictions as data comes in,
you will need to configure the run_specs slightly differently.
It is also worth noting that the initial local model will be created from the available data for that iteration. This means that if you have 5 local clusters, you will need at least 5 data points at each iteration.
An example config for continuous unsupervised inference is shown below:
model_specs:
name: my_kfed_model
type: kFED
version: '5'
run_specs:
only_last_batch: false
onnx_pred: false
prediction_period: 1m