OctaiPipe Steps#
Pipeline steps are the building blocks of the OctaiPipe framework. A pipeline step is an object that processes the data; it has data input and data output. There are a range of available native pipeline steps in OctaiPipe. The user can also create their own steps.
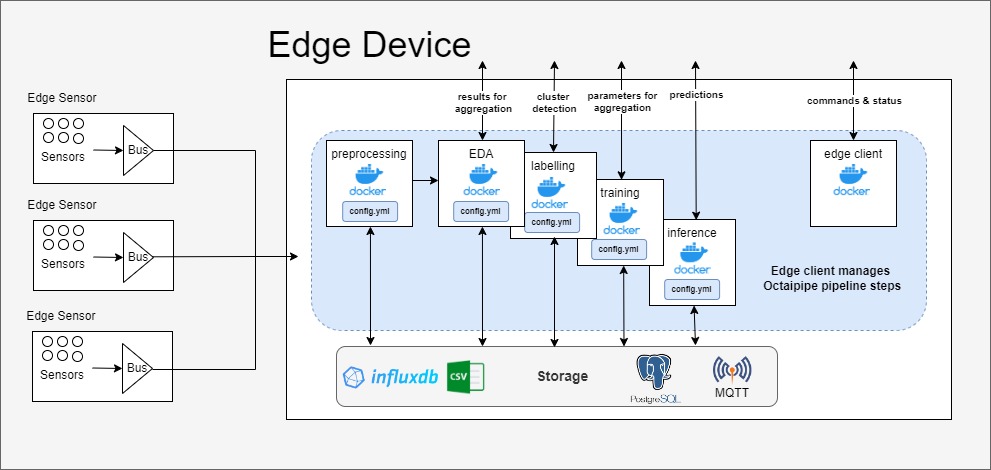
OctaiPipe Pipeline Steps#
With pipeline steps, testing and debugging become easier as each step has a well defined scope and function. Besides, modularity eliminates redundancy in computation and allows the user to accelerate the model development phase. It also allows full auditability and reproducibility of experiment results as each step configuration has a single entry point which is a templatized configuration file. As illustrated in the diagram, each pipeline step interacts with the database to load or write data.
Pipeline Steps#
A typical OctaiPipe machine learning workflow consists of multiple pipeline steps. To execute a step, simply use the OctaiStep command:
1octaistep --step-name <step name> --config-path <config path>
Alternatively, you can use the Python command from the OctaiPipe develop submodule:
from octaipipe import develop
step_name: str = 'preprocessing'
config_path: str = './path/to/preprocessing_config.yml'
develop.run_step_local(step_name=step_name,
config_path=config_path)
Currently we serve the following native OctaiPipe Pipeline Steps:
To run one of these steps locally, use the following step names:
Preprocessing:
preprocessingFeature engineering:
feature_engineeringModel training:
model_trainingModel evaluation:
model_evaluationModel inference:
model_inferenceWASM Model inference:
model_inferenceAndroid Model inference:
image_inferenceData drift:
data_driftFeature selection:
feature_selectionData writing:
data_writingAutoML: cannot run locally, no local step name
Custom step: user-defined step name
Writing Config Files#
When running most workloads in OctaiPipe, you will need to write config files that define what it is you would like to run. In order to help you create these config files, you can get template configs from the develop section of the Pythonic OctaiPipe Python Interface.
You can also validate your config files using the validate_config_file function
from the develop module. Simply give the function the local path to your config file,
and it will return either an OK or any errors in formatting.
For OctaiPipe version 2.5, the following config files can be validated using this:
Federated Learning
Federated EDA
Data writing
Model training
Model inference
Data Input and Output Specs#
Every pipeline step loads data from a data source and writes some data out.
In the config files, specs of the I/O, as discussed in Data Loading and Writing Utilities,
are given in input_data_specs and output_data_specs
respectively. These are present in the config files of all the Pipeline Steps.
Input Data Specs#
OctaiPipe provides a range of options to satisfy your storage needs. In the current release,
the input data that will be queried by each of the pipleine steps can be stored in an InfluxDB
or SQL Database. The argument datastore_type is used to specify the data storage type.
We look at these two cases separately.
InfluxDB Database:
Here is an example of the input_data_specs section that reads from an InfluxDB database:
1 input_data_specs:
2 device_0:
3 - datastore_type: influxdb
4 connection_params:
5 url: http://123.45.67.89:8086
6 settings:
7 query_type: dataframe
8 query_template_path: ./configs/data/query.txt
9 query_config:
10 start: "2022-01-05T17:10:00.000Z"
11 stop: "2022-01-05T17:40:00.000Z"
12 bucket: live-metrics
13 measurement: def-metrics
14 tags:
15 MY_TAG: value_0
query_type is the type of the data loaded from InfluxDB. It can be ‘influx’, ‘csv’, ‘dataframe’, ‘stream’ or ‘stream_dataframe’, corresponding to query, query_csv and query_data_frame , query_stream and query_data_frame_stream methods respectively.
In the above example, we have specified both the start and end timestamps of the query. A typical use case of it is in a model
training pipeline. During inference, and in some other situations, we may also want to run a pipeline step at a regular interval,
using data within a certain past time window from now. To do this, one specifies the input_data_specs like the following:
1 input_data_specs:
2 device_0:
3 - datastore_type: influxdb
4 settings:
5 query_type: dataframe
6 query_template_path: ./configs/data/influx_query_periodic.txt
7 query_config:
8 start: -2m
9 bucket: live-metrics
10 measurement: def-metrics
11 tags:
12 MY_TAG: value_0
Namely, we do not specify the stop in query_config, and for start in
query_config, instead of a timestamp, we specify the size of the past time window
ending now, in minute (e.g. -2m), or in second (e.g. -10s), for which we query the
data. In addition, in run_specs of the pipeline step, one needs to specify the run_interval;
see the pages of the individual pipeline step to which it applies.
Output Data Specs#
The output of the OctaiPipe pipeline steps could be saved to various Data Store types. The output_data_specs field expects a list of specs. Data will be written to each of the sinks defined.
Here is an example of the output_data_specs section that writes to an InfluxDB, SQL and CSV:
1output_data_specs:
2 device_0:
3 - datastore_type: influxdb
4 settings:
5 bucket: test-bucket-1
6 measurement: testv1
7 - datastore_type: sql
8 settings:
9 db_table: test_table
10 data_type: dataframe
11 - datastore_type: csv
12 settings:
13 file_path: test-bucket-1
14 delimiter: ','
15 append: true